
개인정보보호, 소프트웨어 정책


아파치 스팍(Apache Spark)은 속도, 사용의 용이성, 그리고 정교한 분석을 중심으로 오픈 소스 빅 데이터 처리 프레임 워크입니다. 원래 UC 버클리의 AMPLab에서 2009 년에 개발되어 2010년 아파치 프로젝트로 공급 개발 되었다.
스팍은 빅데이터 분석 플랫폼으서 범용적 목적의 분산 고성능 클러스터링 플랫폼 (General purpose high performance distributed platform)으로 하둡과 스톰같은 다른 빅 데이터 및 맵리 듀스 기술에 비해 몇 가지 장점이 있습니다.
우선, 스팍은 빅데이터 처리를 하는데 있어 다양한 데이터 세트(텍스트 데이터, 그래프 데이터 등)의 지원 뿐만 아니라 배치 작업을 관리하는 종합적인 통합 된 프레임 워크를 제공 및 실시간 데이터 스트리밍을 지원하며, 스팍은 디스크에 실행되는 하둡과 달리 100배나 빠른 메모리에 저장하고 실행할 수 있습니다.
스팍의 주요 기능
- Map & Reduce (cf. Hadoop)
- Streaming 데이타 핸들링 (cf. Apache Storm)
- SQL 기반의 데이타 쿼리 (cf. Hadoop의 Hive)
- 머신 러닝 라이브러리 (cf. Apache Mahout)
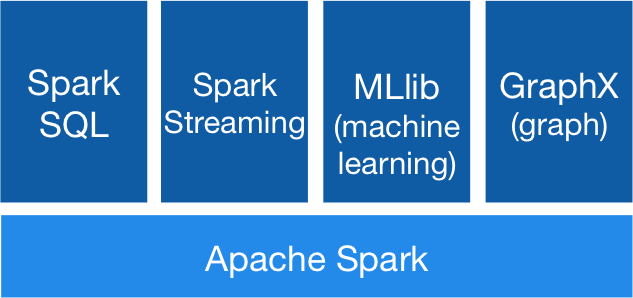
스팍의 장점
스팍은 빠른 속도와 플랫폼으로써의 유연성이 큰 장점이다.
기존의 빅데이터 분석 플랫폼의 구조는 배치 분석 시 ETL 등을 통한 데이터를 로딩, Hadoop의 Map & Reduce 를 이용하여 분산 처리한 다음 OLAP 등의 데이터 베이스에 넣은 후에, 리포팅 툴로 그래프로 표현했다. 실시간 분석 시에는 Storm을 이용하였다.
그러나 스팟은 플랫폼 내에서 배치, 스트리밍, 머신러닝 등 다양한 처리를 제공하여 하나의 데이터를 여러 가지 형태로 데이터를 처리가 가능하다.
또한 스팍은 스칼라로 구현되었지만, 파이썬, 자바, 스칼라 등 다양한 언어를 지원하며, 데이터 저장소로는 하둡, 아마존 S3, 카산드라 등을 지원한다.
관련 링크
Big Data Processing using Apache Spark – Part 1: Introduction
Big Data Processing using Apache Spark – Part 2: Spark SQL
Big Data Processing using Apache Spark – Part 3: Spark Streaming
Big Data Processing using Apache Spark – Part 4: Spark Machine Learning
Big Data Processing using Apache Spark – Part 5: Spark ML Data Pipelines Sep 24, 2016
Apache Spark Main Website
Spark Machine Learning Website
Spark Machine Learning Programming Guide
Spark Workshop Exercise on Spam Detection