
개인정보보호, 소프트웨어 정책


빅 데이터는 혁신적인 기술이 사용 가능한 정보의 쓰나미에서 가치를 추출하는 새로운 방법을 제공하는 새로운 분야입니다. 새로운 영역과 마찬가지로 용어와 개념은 다르게 해석될 수 있습니다. 빅 데이터 도메인도 다르지 않습니다.
지난 몇 년 동안 다양한 속성으로 데이터에 레이블을 지정하기 위해 등장한 “빅 데이터”의 다양한 정의를 살펴 봅니다. 빅 데이터 가치 사슬은 빅 데이터 시스템 내의 정보 흐름을 데이터에서 가치와 유용한 통찰력을 생성하는 데 필요한 일련의 단계로 설명하기 위해 도입되었습니다.
가치 사슬을 통해 사슬 내 각 단계에 대한 빅 데이터 기술을 분석 할 수 있습니다.
빅 데이터 생태계의 개념을 살펴 봅니다. 비즈니스 환경을 설명하고 빅 데이터 컨텍스트로 확장 할 수있는 방법을 설명하기 위해 비즈니스 커뮤니티 내에서 생태계를 보아야합니다. 빅 데이터 생태계의 주요 이해 관계자는 유럽에서 빅 데이터 생태계를 활성화하기 위해 극복해야 할 과제와 함께 식별됩니다.
빅 데이터 란?
지난 몇 년 동안 서로 다른 주요 업체에서 “빅 데이터”라는 용어를 사용하여 서로 다른 속성으로 데이터에 레이블을 지정했습니다. 지난 10 년 동안 빅 데이터에 대한 몇 가지 정의가 제안되었습니다. 표 3.1을 참조하십시오. META Group의 Doug Laney (당시 Gartner에 인수)의 첫 번째 정의는 3 차원 관점을 사용하여 빅 데이터를 정의했습니다. 향상된 의사 결정, 통찰력 발견 및 프로세스 최적화를 가능하게합니다”(Laney 2001). Loukides (2010)는 빅 데이터를 “데이터 자체의 크기가 문제의 일부가되고 데이터를 처리하는 전통적인 기술이 부족할 때”라고 정의합니다. Jacobs (2009)는 빅 데이터를 “그 크기로 인해 당시 널리 퍼져있는 검증 된 방법을 넘어서는 데이터”라고 설명합니다.
빅 데이터는 새로운 규모와 복잡성에서 데이터 작업에 필요한 데이터 관리 과제를 하나로 묶습니다. 이러한 도전의 대부분은 새로운 것이 아닙니다. 그러나 새로운 것은 3V와 관련된 빅 데이터의 특정 특성으로 인해 제기되는 과제입니다.
• Volume (데이터 양) : 데이터 처리 내에서 대규모 데이터 처리 (예 : 글로벌 공급망, 글로벌 재무 분석, 대형 Hadron Collider).
• Velocity (데이터 속도) : 들어오는 실시간 데이터 (예 : 센서, 퍼베이시브 환경, 전자 거래, 사물 인터넷)의 높은 빈도 스트림을 처리합니다.
• Variety (데이터 유형 / 소스 범위) : 서로 다른 구문 형식 (예 : 스프레드 시트, XML, DBMS), 스키마 및 의미 (예 : 엔터프라이즈 데이터 통합)를 사용하여 데이터를 처리합니다.
빅 데이터 대 빅 데이터는 기존 기술 접근 방식의 기본에 도전하고 향상된 의사 결정, 통찰력 발견 및 프로세스 최적화를 가능하게하는 새로운 형태의 데이터 처리를 요구합니다. 빅 데이터 분야가 성숙 해짐에 따라 Veracity (문서화 품질 및 불확실성), Value 등과 같은 다른 Vs가 추가되었습니다. 빅 데이터의 가치는 지식 기반 조직의 역학 맥락에서 설명 될 수 있습니다 (Choo 1996), 의사 결정 및 조직 활동의 프로세스가 감각 결정 및 지식 생성 프로세스에 의존하는 곳.
빅 데이터의 정의
- “빅 데이터는 향상된 의사 결정, 통찰력 발견 및 프로세스 최적화를 가능하게하기 위해 새로운 형태의 처리가 필요한 대용량, 고속 및 / 또는 매우 다양한 정보 자산입니다.” Laney (2001), Manyikaet al. (2011)
- “데이터 자체의 크기가 문제의 일부가되고 데이터 작업을위한 전통적인 기술이 부족할 때”. Loukides (2010)
- 빅 데이터는 “당시 널리 퍼져있는 검증 된 방법을 넘어서는 크기를 가진 데이터”입니다. Jacobs (2009)
- “빅 데이터 기술은 [] 고속 캡처, 검색 및 / 또는 분석을 가능하게하여 방대한 양의 데이터에서 경제적으로 가치를 추출하도록 설계된 차세대 기술 및 아키텍처입니다.” IDC (2011)
- “너무 크고 복잡한 데이터 세트 모음에 대한 용어는 현재 데이터베이스 관리 도구 또는 기존 데이터 처리 응용 프로그램을 사용하여 처리하기 어려워집니다.” 위키 백과 (2014)
- “현장 데이터베이스 관리 도구를 사용하여 난이도 만 처리 할 수있는 크고 복잡한 데이터 세트 모음”. Mike 2.0 (2014)
- “빅 데이터는 표준 IT 기술로는 접근 할 수없는 합리적인 시간 내에 잠재적으로 큰 데이터 세트를 캡처, 처리, 분석 및 시각화하는 기술 사용을 포괄하는 용어입니다.” 확장하여 이러한 목적으로 사용되는 플랫폼, 도구 및 소프트웨어를 통칭하여 “빅 데이터 기술”이라고합니다. NESSI (2012)
- “빅 데이터는 큰 볼륨, 큰 속도 또는 큰 다양성을 의미 할 수 있습니다.” Stonebraker (2012)
빅 데이터 가치 사슬
비즈니스 관리 분야에서 가치 사슬은 가치있는 제품이나 서비스를 시장에 제공하기 위해 조직이 수행하는 일련의 활동을 모델링하는 의사 결정 지원 도구로 사용되었습니다 (Porter 1985).
가치 사슬은 조직의 일반적인 부가가치 활동을 분류하여 이해하고 최적화 할 수 있도록합니다. 가치 사슬은 각각 입력, 변환 프로세스 및 출력이있는 일련의 하위 시스템으로 구성됩니다.
Rayport와 Sviokla (1995)는 가상 가치 사슬에 대한 작업 내에서 정보 시스템에 가치 사슬 비유를 적용한 최초의 기업 중 하나입니다. 분석 도구로서 가치 사슬을 정보 흐름에 적용하여 데이터 기술의 가치 창출을 이해할 수 있습니다.
데이터 가치 사슬에서 정보 흐름은 데이터에서 가치와 유용한 통찰력을 생성하는 데 필요한 일련의 단계로 설명됩니다. 유럽 연합 집행위원회는 데이터 가치 사슬을 “미래 지식 경제의 중심으로 디지털 발전의 기회를보다 전통적인 부문 (예 : 운송, 금융 서비스, 건강, 제조, 소매)으로 가져옴”(DG Connect 2013)으로보고 있습니다.
빅 데이터 가치 사슬 (Curry et al. 2014)은 그림 3.1과 같이 정보 시스템을 구성하는 높은 수준의 활동을 모델링하는데 사용할 수 있습니다. 빅 데이터 가치 사슬은 다음과 같은 주요 상위 활동을 식별합니다.
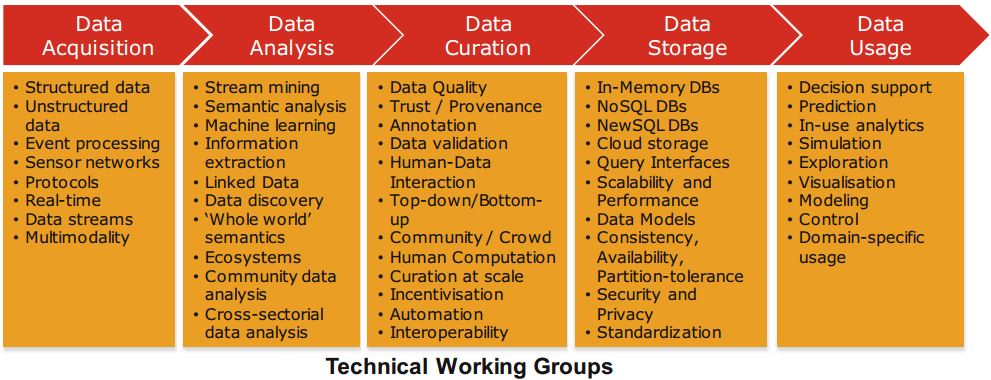
데이터 수집
데이터를 데이터웨어 하우스 또는 데이터 분석을 수행 할 수있는 다른 스토리지 솔루션에 배치하기 전에 데이터를 수집, 필터링 및 정리하는 프로세스입니다. 데이터 수집은 인프라 요구 사항 측면에서 빅 데이터의 주요 과제 중 하나입니다. 빅 데이터 수집을 지원하는 데 필요한 인프라는 데이터 캡처와 쿼리 실행 모두에서 예측 가능한 짧은 대기 시간을 제공해야합니다. 종종 분산 환경에서 매우 많은 트랜잭션 볼륨을 처리 할 수 있습니다. 유연하고 동적 인 데이터 구조를 지원합니다.
데이터 분석
획득 한 원시 데이터를 도메인 별 용도뿐만 아니라 의사 결정에 사용할 수 있도록 만드는 것과 관련이 있습니다. 데이터 분석에는 관련 데이터를 강조 표시하고 비즈니스 관점에서 잠재력이 높은 유용한 숨겨진 정보를 합성 및 추출하기위한 목적으로 데이터 탐색, 변환 및 모델링이 포함됩니다. 관련 영역에는 데이터 마이닝, 비즈니스 인텔리전스 및 기계 학습이 포함됩니다.
데이터 큐 레이션
효과적인 사용에 필요한 데이터 품질 요구 사항을 충족하도록 수명주기 동안 데이터를 적극적으로 관리하는 것입니다 (Pennock 2007). 데이터 큐 레이션 프로세스는 콘텐츠 생성, 선택, 분류, 변환, 검증 및 보존과 같은 다양한 활동으로 분류 할 수 있습니다.
데이터 큐 레이션은 데이터의 접근성과 품질 향상을 담당하는 전문 큐레이터가 수행합니다. 데이터 큐레이터 (과학 큐레이터 또는 데이터 어노 테이터라고도 함)는 데이터가 신뢰할 수 있고, 검색 가능하고, 액세스 가능하고, 재사용 가능하고, 목적에 부합하는지 확인할 책임이 있습니다. 빅 데이터 큐 레이션의 주요 트렌드는 커뮤니티 및 크라우드 소싱 접근 방식을 활용합니다.
(Curry et al. 2010).
데이터 스토리지
데이터에 대한 빠른 액세스가 필요한 애플리케이션의 요구를 충족하는 확장 가능한 방식으로 데이터를 지속하고 관리하는 것입니다. 관계형 데이터베이스 관리 시스템 (RDBMS)은 거의 40 년 동안 스토리지 패러다임에 대한 거의 고유 한 주요 솔루션이었습니다. 그러나 데이터베이스 트랜잭션을 보장하는 ACID (Atomicity, Consistency, Isolation 및 Durability) 속성은 스키마 변경과 관련하여 유연성이 부족하고 데이터 볼륨과 복잡성이 증가 할 때 성능 및 내결함성이 부족하여 빅 데이터 시나리오에 적합하지 않습니다. NoSQL 기술은
확장 성 목표를 염두에두고 대체 데이터 모델을 기반으로 한 광범위한 솔루션을 제시합니다.
데이터 사용
데이터에 대한 액세스가 필요한 데이터 기반 비즈니스 활동, 분석 및 비즈니스 활동 내에서 데이터 분석을 통합하는 데 필요한 도구를 포함합니다. 비즈니스 의사 결정에서 데이터 사용은 비용 절감, 부가가치 증가 또는 기존 성능 기준에 대해 측정 할 수있는 기타 매개 변수를 통해 경쟁력을 향상시킬 수 있습니다.
출처 : The Big Data Value Chain: Definitions, Concepts, and Theoretical Approaches, Edward Curry, 2015