
개인정보보호, 소프트웨어 정책


빅데이터를 분석하기 위하여 하둡(Hadoop)의 분산처리 지원은 수집, 저장에서 유용하나 분석시 분산처리를 적용할 경우 해당 알고리즘의 구조가 분산처리를 하여도 정보의 왜곡이 발생하는가를 검토하여야 한다. 분석 시 적용하는 알고리즘이 분산처리가 가능한 알고리즘이 있고 분산처리를 할 수 없는 알고리즘이 있다.
우리가 산술식을 처리하는 데있어 [그림 1]과 같이 단일처리시에는 수식을 어떻게 계산하든 결과값에 영향을 받지 않으나 [그림 2]와 같이 맵-리듀스를 이용한 분산병렬처리를 하는 경우에는 수식을 어떻게 적용하느냐에 따라 그 결과 값이 상이하게 나타날 수 있다.
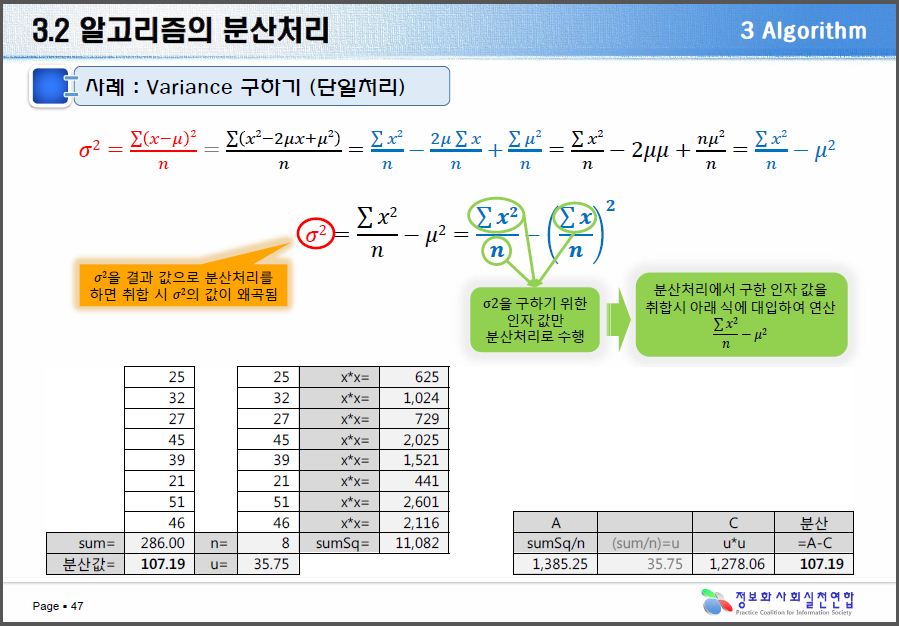
[그림 1] 단일처리방법의 알고리즘 결과
아래 [그림 2]는 통계량의 분산(Variance)를 구하는 수식의 구현 방식에 따라 그 값이 상이하게 나타나는 것을 보여주는 간단한 예시이다.
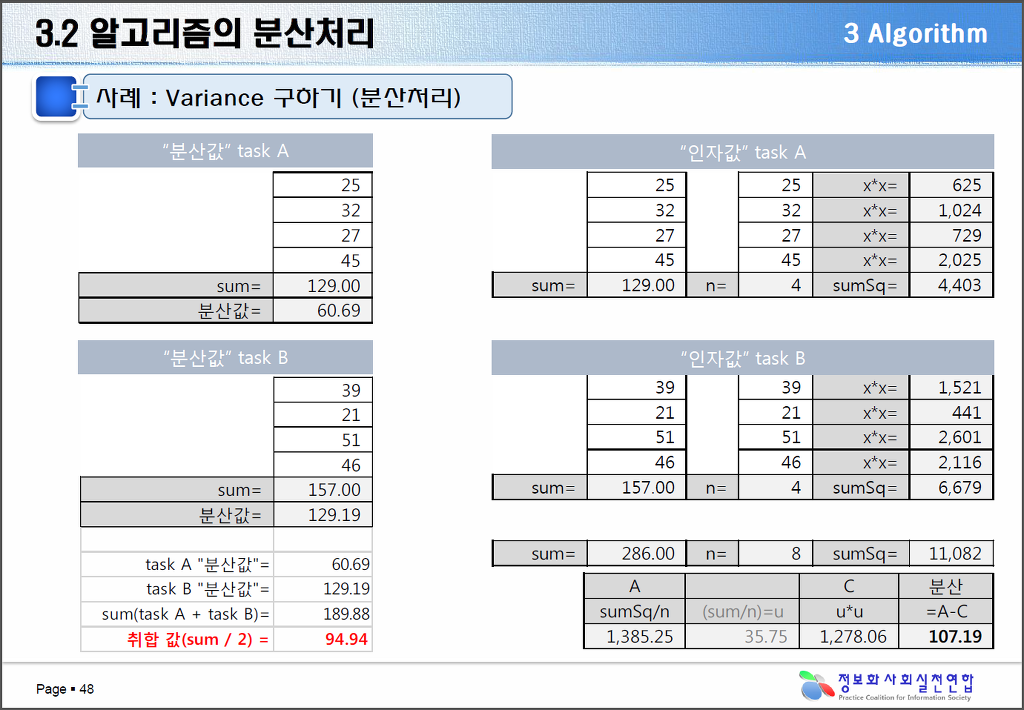
[그림 2] 분산처리방법의 알고리즘 결과
그러므로 분산처리가 불가능한 알고리즘을 분산처리방식으로 수행하면 전혀 다른 결과 값이 나오며, 그 결과를 서비스로 제공하게 되면 정보에 대한 왜곡이 발생하게 된다.
위 자료는 분산처리를 적용하여 정보를 분석하는데 있어 구현방식에 따라 결과값의 왜곡이 발생하게 되는 경우를 설명하는 예시이다.
붙임자료